SHNGS2017 - Implicit Bias on Linearly Separable Datasets
One of the key ideas in overparametrized ML is that there are implicit biases introduced by optimization which encourage algorithms to find global minima which generalize well. That is even though there are many solutions which will yield zero training error, we tend to find “good” solutions in terms of risk.
Summary
SHNGS2017 show for linearly separable datasets, the GD solution to an unregularized logistic regression problem converges in direction to the max-margin SVM solution. This result is fairly unique because unlike least squares problems, when using logistic or cross-entropy loss in underdetermined settings, there is no finite minimizer. Hence their analysis crucially relies on analyzing the direction of the predictor, all that matters in a classification setting.
Key Theorem 1: For any linearly separable dataset, any -smooth monotone decreasing loss function with an exponential tail (strictly bounded below by zero), any stepsize and any starting point , the gradient descent iterates behave as:
where is the max margin vector:
and the residual grows at most as and so:
Further for almost all datasets, the residual is bounded.
Proof Sketch: First, the exponential tail of the loss function is key for the asymptotic convergence to the max margin vector. Assume the loss function: . For linearly separable data, we will have . If converges to a limit , then one can write such that , and . The gradient becomes:
As , the will decay much quicker for samples with small exponents. The only samples which contribute to the gradient will be the support vectors, i.e. those with the smallest margin, .
Looking at the negative gradient above, we see that it will become a weighted average of the support vectors. Since , the initial conditions become irrelevant and will become dominated by the supports vectors, as will its margin-scaled version, . It follows:
These are exactly the KKT conditions for hard-margin SVM.
Key Theorem 2: For almost every linearly separable dataset, the normalized weight vector converges to the normalized max margin evector in norm:
and in angle:
On the other hand the loss decreases as:
Practical Implications:
-
While the loss decreases at a fast rate towards zero, the convergence of to the max-margin is slow. You may need to wait until the loss is exponentially small in order to be close to the max-margin solution. So, continuing to optimize the training loss even after the training error is zero and training loss is very small can improve generalization. The margin can continue to grow.
-
Since converges to the max-margin , we expect population misclassification error to improve as . However, we have no guarantees that will have zero population or test misclassification error. Since , for convex loss functions, the loss for the misclassified points will increase as . More precisely, let and note that as . For , we have:
This means that you can see the population or test loss increase even while the predictor’s generalization is improving. Practically, if you monitoring a validation set to stop training, you should look at the misclassification error, not the loss.
Connections to Other Results: AdaBoost can be formulated as a coordinate descent algorithm on the exponential loss of a linear model. With small enough step sizes, AdaBoost does converge precisely to the max-margin solution. For similar loss functions and the regularization path where is the norm penalty, one can show that is proportional to the max margin solution. These latter results are considering explicit regularization as opposed to implicit regularization induced by optimizaiton.
Extensions: The paper proves similar results for the multi-class setting with cross-entropy loss as well as neural nets where only a single weight layer is optimized and after a sufficient number of iterations the activation units stop switching.
Other Optimization Algorithms: Experimentally, these results continue to hold for SGD and momentum variants of GD. However, adaptive methods such as AdaGrad and ADAM do not converge to the max-margin solution.
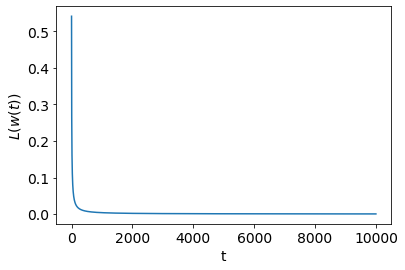
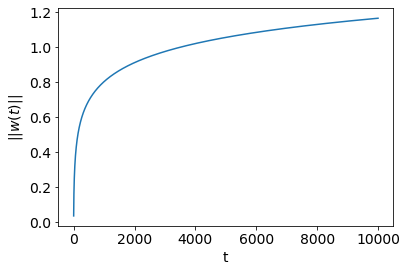
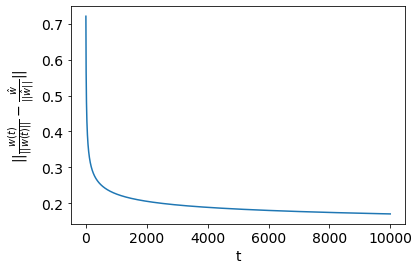
A Quick Empirical Check: I ran a quick simulation to check if these results hold up empirically. I generated a linearly separable dataset of samples and features. Then, I ran unregularized logistic regression keep track of along the optimization path. As expected, both the hard SVM solution and final logistic regression solution have zero training error. The first plot here shows the which decays as . The second plot shows which increases as . The last plot shows the margin gap which decays as . It is hard to eyeball the difference in and , but I plotted those functions explicitly and they do in fact match these results.