Attention Mechanisms + Transformers
This is part 6 of my applied DL notes. They cover attention mechanisms and transformers.
Introduction
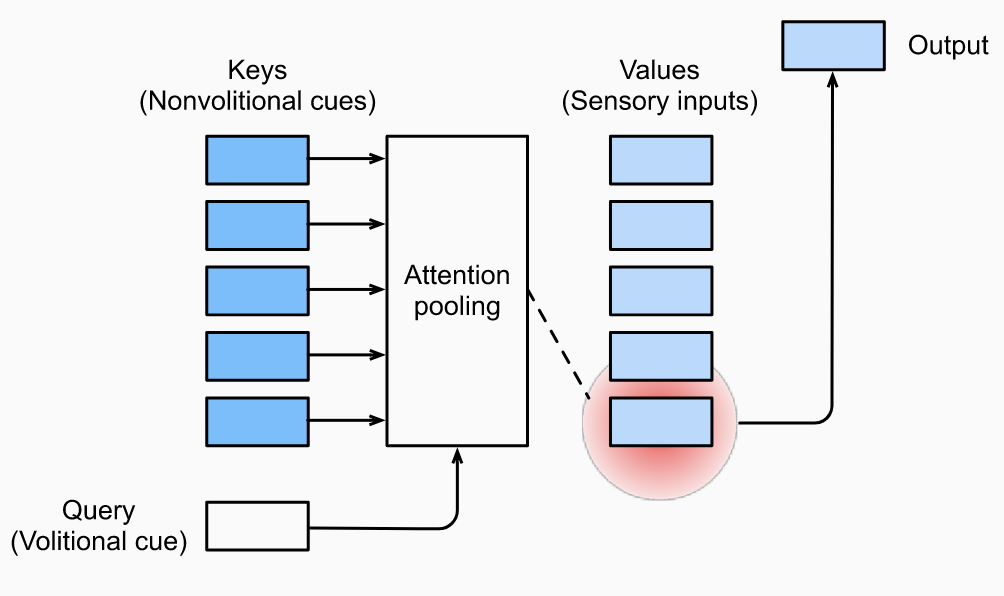
Attention mechanisms are different from FC or pooling layers since they take advantage of queries. They are a way to bias selection over values via a process called attention pooling, which measures interactions between queries and keys. The keys are paired to values.
One way to think of attention pooling is by analogy to Nadraya-Watson Kernel Regression (NWKR). Consider a training dataset and a test point . Then, the NWKR prediction takes the form:
Here we have is the query, are the keys, are the values, and are the attention weights. In NWKR, where is a kernel function. However, we can imagine that . It is parameterized by a parameter which can be learned with backprop. When predicting the output of a training sample , we would need to exclude it from the key-value pairs to avoid degenerate solutions for .
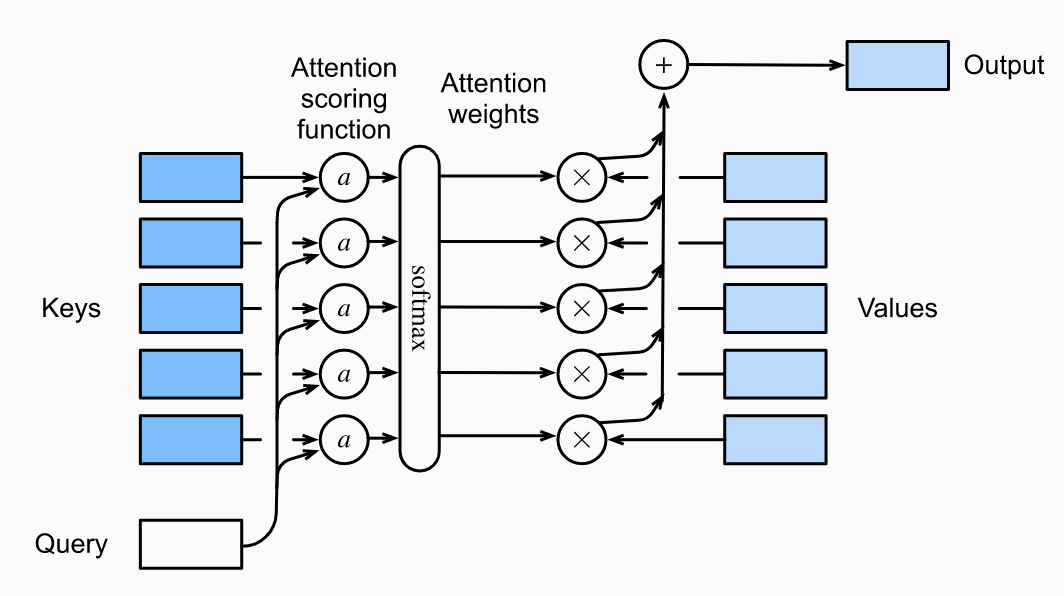
To formally define attention mechanisms, say we have a query and key-value pairs where and . Attention pooling is a weighted sum:
Here the attention weights are computed as follows:
where is a scoring function that maps two vectors to a scalar based on their similarity/importance.
Sometimes we will want a masked softmax operation to compute the attention weights. For example, in machine translation, we often have <pad> tokens which carry no meaning and should not be fed into attention pooling. The attention weights can be visualized by producing a matrix with queries as rows, keys as columns and attention weights as values.
Scoring Functions
Additive Attention
When queries and keys are vectors of different lengths, additive attentions is given by:
where , and . Concatenating the query and key, we can see this equation is just a single-layer MLP, with activation and no bias terms.
Scaled Dot-Product Attention
If the two vectors of the same dimension, a more computationally efficient scoring function is just the dot product. But assuming that both and are independent zero mean and unit variance vectors, will be zero mean and variance . Hence when is large and the magnitude of the dot product is large, we may end up pusing the into regions where it has very small gradients, making learning difficult. So, we scale:
We will typically processes whole minibatches at time. Consider queries, key-value pairs, queries/keys of size and values of size . Then, the scaled dot-product attention weights are given by:
where , and .
Bahdanau Attention
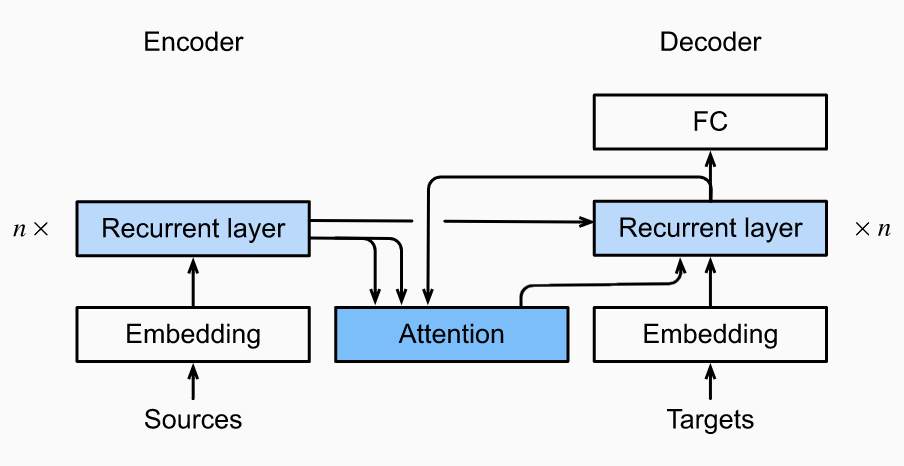
Recall our usual encoder-decoder RNN architecture uses the same context variable (which encodes the input sequence) in each decoding step. But not all input tokens may be useful for decoding a particular token. By treating the context variable as the output of attention pooling, we can get our model to align to parts of the input sequence most relevant to the current prediction.
We have the context variable at decoding time is given by:
Here the decoder hidden state from time step is the query, the encoder hidden states are the key-value pairs, and we can compute using the additive attention scoring function as .
Implementation Notes
- For initializing the decoder, you need to do two things. First, pass in the encoder final-layer hidden states at all the time steps, so they can be used for the key-value pairs in attention. Second, as usual, pass the encoder all-layer hidden state at the final step to initialize the decoder hidden state.
- As you are running the decoder, the attention output at any step depends on the previous decoder hidden state. So, you will need to iterate over time steps one by one. Each time, you will concatenate the new attention output to the target embedding to pass through the RNN cell.
Multi-Head Attention
Given some set of queries/keys/values, it is possible we want our model to combine different types of attentions. For example, maybe we want to capture shorter and longer range dependencies within a sequence. Instead of learning a single attention pooling, the queries/keys/values can be transformed with learned linear projections. These sets of queries/keys/values are then pushed into attention pooling in parallel. Finally, these attention pooling outputs are concatenated and pushed through a FC layer to get the final output. This is called multi-head attention.
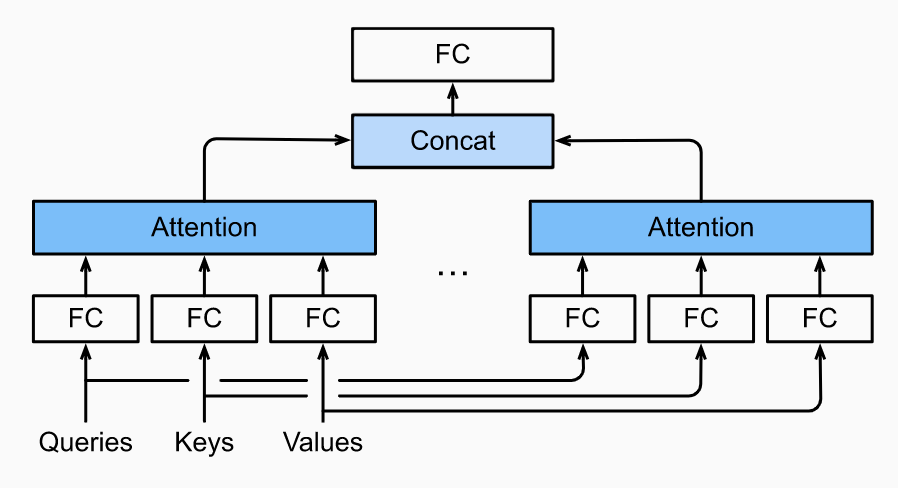
Formally, say we have a query , key , value , each attention head for is computed as:
for learnable parameters , , and is attention pooling as we know from earlier. Finally, we have the output:
where . In this way, each head can align with different patterns in the input sequence.
Typically, we set . This helps control the computational cost and number of parameters. With the reduced dimension of each head, , the total computational cost is similar to that of a single head with full dimensionality.
One of the key facets of multi-head attention is that it can be computed in parallel, as we will see when we look at Transformer architectures. Leveraging parallelization will require proper tensor manipulation in PyTorch.
Self-Attention
Self-attention refers to passing in the same set of tokens for queries, keys and values. To use self-attention for sequence modeling, we have to include additional information on sequence order.
Formally, self-attention is as follows. Given a set of input tokens , self attention outputs a sequence such that:
where is attention pooling.
CNNs vs RNNs vs Self-Attention
To realize the benefits of self-attention, consider modeling an output sequence of tokens given an input sequence of tokens. All tokens are of dimension . We compare computational complexity, sequential operations and maximum path length of CNNs, RNNs and self-attention. Recall that sequential operations will make it difficult to parallelize computation and a long maximum path length will make it difficult to learn long-range dependencies.
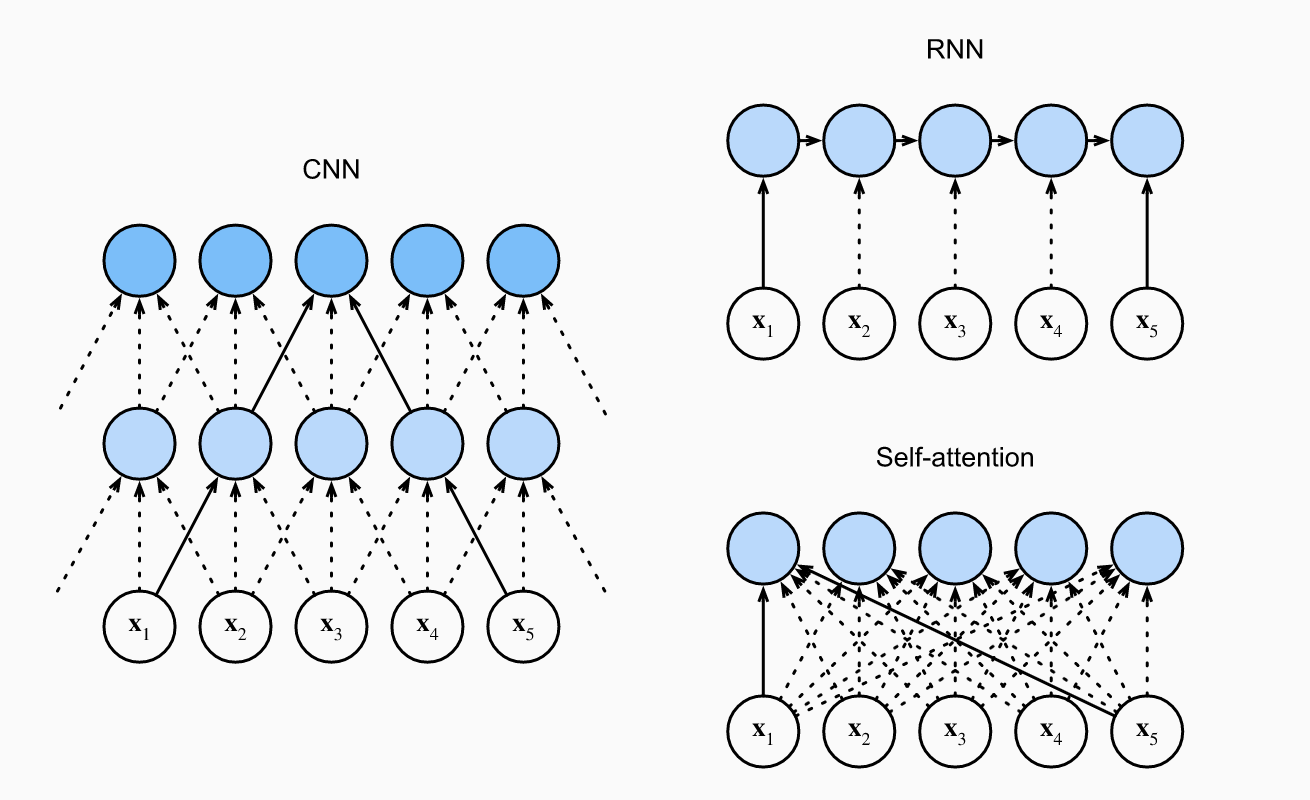
First, note that the CNNs we will have input and output channels. Note we can just think of a sequence as a image. Then, given a kernel size , the compute time is . The CNN operations are hierarchical, so there are sequential operations. Finally, the max path length is .
For RNNs, we have to multiply a weight matrix by a -dimensional hidden state, which has complexity . We do this times, so the compute time is . There are sequential operations that cannot be parallelized and the max path length is also .
In self-attention, all queries/keys/values are matrices. We first multiply a matrix by a matrix. Then, we multiply the output by a matrix. The compute complexity is . Each token is connected to each other token so the sequential operations are and the max path length is also .
Hence both CNNs and self-attention can be parallelized. Self-attention has the shortest max path length, but quadratic compute complexity with regards to makes it slow for long sequences.
Positional Encoding
In self-attention, we have forgone any sequential info for the ability to parallelize. To add sequence order back to the model, we include a positional encoder along with our input embedding. The positional encoder can be learned or fixed. Here we consider a fixed one based on sin and cosines. We will generate a matrix and instead of passing the original input embedding , we will pass . The entries as follows:
Here each row is a position in the sequence. Each column is a trig function of some frequency. Higher order columns are lower frequencies. The intuition is as follows. Think of 0-7 in binary: 000, 001, 010, 011, 100, 101, 110, 111. Notice the last bit alternates every number; it is high frequency. The middle bit alternates every two numbers; it is lower frequency. The firs tbit alternatives every four numbers; it is the lowest frequency. So, we are basically just converting each number to binary and using a continuous representation.
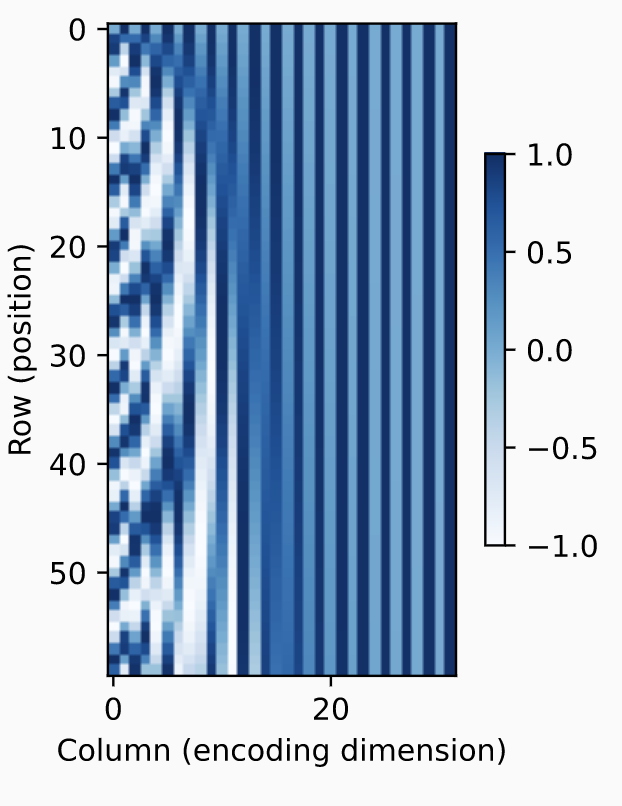
In fact one can show that in addition to telling us about absolute position, this encoding also tells us about relative position. This is beacuse the positional encoding at any position can be represented as a linear transform of the position at .
Transformers
Transformers are a deep architecture which abandon any recurrent or convolutional operations in favor of self-attention. They are a go-to model for many applied DL domain areas.
An transformer architecture is below. It is an encoder-decoder architecture but either one can be used individually. The source/target embeddings go through positional encoding before being pushed through the individual stacks.
The encoder stack is layers. Each layer consists of: 1) multi-head attention and 2) a positionwise feed-forward network. In each layer, the queries/keys/values come from the previous layer output. Both sub-layers employ a residual connection. To make this feasible, for any sub-layer input , we require the sub-layer output , so is possible. The residual connection is followed by layer-normalization. The output of the enconder is a dimensional representation for each position in the input sequence.
The decoder stack is similar, but each layer consists of a third sublayer, encoder-decoder attention. In encoder-decoder self-attention, the queries are outputs from the previous decoder layer and the keys-value pairs are the encoder outputs. In decoder self-attention, queries/keys/values are all outputs from the previous layer, but the decoder can only align with outputs previous positions. This is called masked attention and ensures that during test time, prediction only depends on tokens which have been generated.
![]()
A positionwise feed-forward NN merely transforms the representation at each sequence position using the same MLP. Layer-normalization is similar to batch normalization. While batch normalization standardizes each feature across examples within a given minibatch, layer normalization standardizes each example across all of its feature dimensions. It is common in NLP.