RNNs
This is part 5 of my applied DL notes. They will cover high-level intuition about RNNs and some practical advice on using them for language modeling/machine translation.
Language Modeling
One of the primary applications of RNNs is for language modeling. The goal is to learn the joint probability of a text sequence . This enables us to do text generation with . Here are some practical insights which motivate and set-up using RNNs for this task:
- Processing:
- Tokenize corpus into words or chars
- Build a vocabulary which is a mapping between words and numerical indices
- Keep a token to represent “unknown” in your vocabulary
- Keep reserved tokens for end of sequence, start of sequence and padding
- Maybe get rid of very rare tokens?
- Learning a language model for the sequence by factorizing the joint distribution as and using counting estimators is not optimal because: 1) we have to store the counts, 2) ignores meaning of words, 3) long combinations of words become rare or non-existent, so modeling the tail of the frequency distribution becomes difficult.
- We can make weaker Markov assumptions to model longer dependences. We can go from unigram to n-gram models.
- Unigram, bigram, trigams all obey frequencies as , i.e. linear on the log-log scale. This very rapid/consistent decay implies there is structure we should be able to learn with NNs.
- We will need to split up very large sequences into smaller sub-sequences for modeling in a NN. Assume that each minibatch has to contain samples with time steps. We can:
- Use random sampling. We truncate the long sequence before a random offset and then randomly shuffle the possible starting points for the smaller -step subsequences. Two examples in the minibatch may not be adjacent in the original text.
- Sequential partitioning. Again, we use a random offset, but then do not shuffle the starting points.
Perplexity
Say a language model is completing a sequence “It is raining … “. A model which completes it with “outside” is better than “asdasdsad”. We can compute the likelihood of “It is raining outside” and see it is higher than “It is raining asdasdsad.” It is hard to evaluate likelihoods, especially since longer sequences will be less likely. We need an average. Hence it is reasonable to use perplexity:
Here is given by a language model and is the actual token at time . So, this is the exponential of the cross entropy entropy loss average over the tokens. If our model is perfect, perplexity is 1. In our model always completely wrong, perplexity is . A model which predicts uniform over the tokens in a vocab will have a perplexity of the number of unique tokens. Intuitively, perplexity tells us a better language model is able to spend fewer bits to compress the sequence.
Machine Translation
Machine translation is a related, but different problem. The goal is to map an input sequence in one language to an output sequence in another language. The text processing is much the same, but there are a few differences:
- We have two vocabularies.
- We can have variable-length inputs/outputs. To ensure that all sequences in a minibatch are the same length, we can fix a given length of time steps. Sequences that are too small can be padded with a <pad> token. Sequences that are too long can be truncated.
- It will be useful to add a <eos> token to indicate the end of a sequence to indicate the end of an input sequence or keep track of the true lengths. Similarly, we can add <bos> tokens.
BLEU
For machine translation, the performance metric is usually BLEU. For any -gram in the predicted sequence, BLEU evaluates whether this -gram appears in the label truth. We denote as the ratio of the number of matched -grams to the number of -grams in the predicted sequence. For example, given a predicted sequence ABBCD and a label sequence ABCDEF, we have and . Then, BLEU is:
where is the longest -grams for matching. If the predicted sequence exactly equals the label sequence, we have BLEU is 1. Also, since grows with for a fixed , BLEU assigns greater value to longer -gram precision. Finally, since predicting shorter sequences will get you higher , the term penalizes shorter predicted sequences.
RNNs
Assume a -gram model where the conditional probability of a word at time step only depends on the last words. For a vocab , a counting model model would need to store numbers. Instead, we can use a latent variable model:
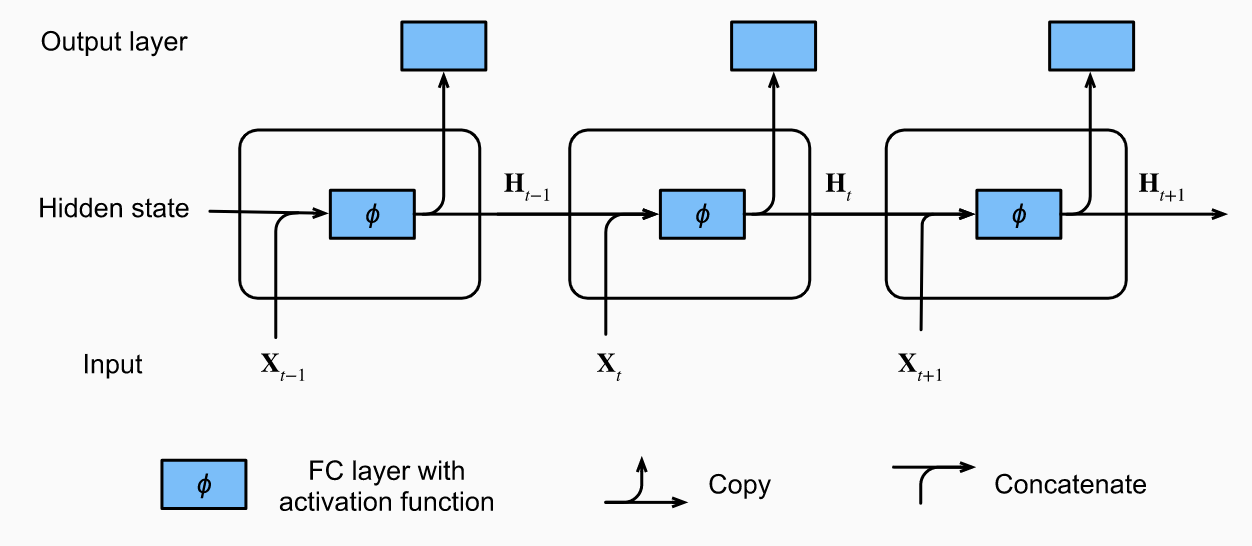
where is a hidden state that summarizes information through time . We can let . Note we want to be a small, but useful representation of the past time steps. It should not just store the full sequence; that would be infeasible memory/compute-wise. RNNs are NNs with hidden states. Let be a minibatch of inputs at time and be the hidden state at time . We have stored from the last step. We model:
So, the hidden state today depends on its dependence on to the hidden state yesterday, parameterized by , and its dependence on the input today, parameterized by . Finally, we generate the output as:
Note that the weights and are constant across time steps. So, parameterization does not increase with . Note we can simplify computation of here by concatenating the matrices into and feeding them into a FC “hidden state” layer paramterized by . Then, we take and feed it into a FC “output” layer parameterized by to get .
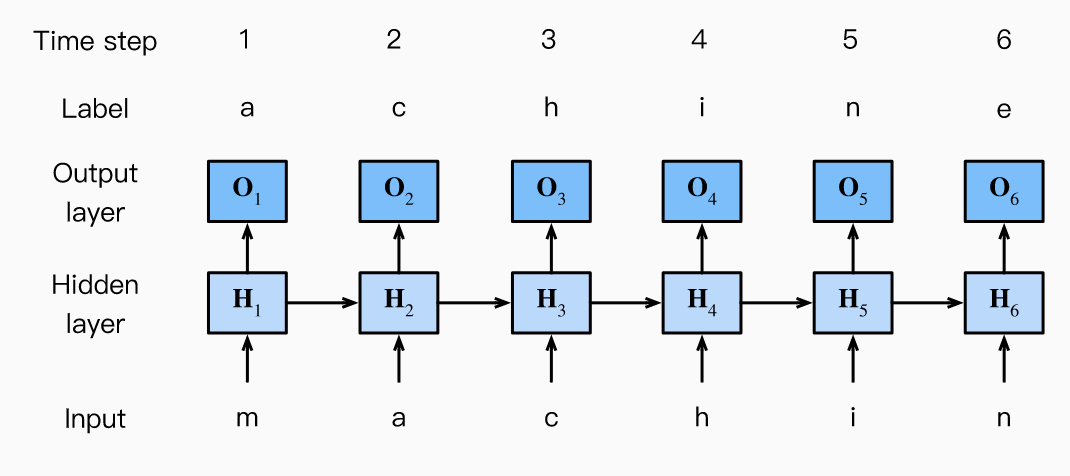
RNNs for Character-Level Language Models
As a concrete example, consider the character RNN below where we want to predict the next token using current and past tokens. Consider a minibatch of size 1 with the sequence given by “machine.” In step 3, depends on “mac” and the cross-entropy loss will depend on the and the true char “h.” In practice, each token is a vector and batch size is greater than 1. So, the input is .
Some implementation advice:
- Recall we build a numerical index map for each token. Feeding indices to the NN might make it hard to learn. Instead, we choose an embedding representing each token as a feature vector. The easiest one is one-hot encoding. Alternatively, this can be a learned matrix where the rows are of length vocab size and the columns are of length embedding dimension. In PyTorch, a
nn.Embeddinglayer is just a map which fetches the th row from the matrix given input token . - It is easiest to reshape your tensors to (num_steps, batch_size, dim), so you can conveniently loop through the outermost dimension to update hidden states and generate outputs.
- During prediction, you may be given a user-supplied prefix. You should use these prefixes in a warm-up period to update your hidden state, so it is better than initialization.
- For training: If you use sequential partitioning, initialize the hidden state only the beginning of each epoch because subsequences passed in minibatches are adjacent. However, then the hidden state depends on all the past minibatches in an epoch, which complicates the gradient computation. To simplify, we detach the gradient before processing each minibatch, so it only depends on the steps in the current batch. For random sampling, we re-initialize the hidden state for each iteration since each example is in random position.
- In PyTorch, the
nn.RNNLayer returns an output and an updated hidden state, where the output is not actually the final output layer computation. It is just for . You need annn.Linearlayer on top of it to get the actual outputs .
Backprop Through Time
Backprop through time is just backprop for RNNs. There is nothing conceptually different, but it is worth studying the computational graph to point out potential issues we run into with long sequences.
Think about a sequence with . The first token can potentially influence the last token. Computing and storing the gradients of can then take too long and requires to much memory. Moreover, it will typically be numerically unstable. To be more mathematically precise, consider an RNN with the identity activation and no bias parameters. For time step , let a single example input be , label , hidden state and output . Then we have:
If the loss at time is , the objective function is:
The computational graph below shows the dependencies. Following the arrows backwards from to parameters and , we can get the gradients of interest.
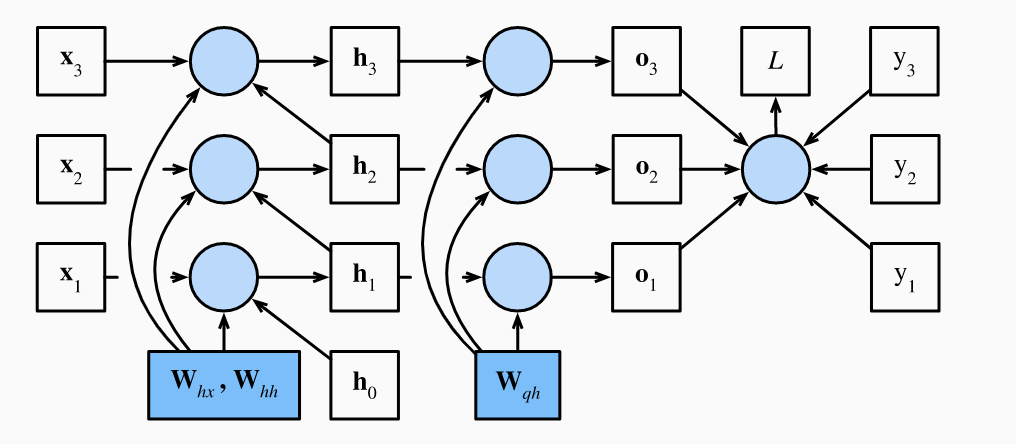
First, we have:
Since depends on through , the chain rule for total derivatives gives us:
For the final time step , we have only depends on through :
For , it is more complicated as depends on through and :
Unrolling the recursion, we get:
Here we see for long sequence models we are going to have very large powers of . Eigenvalues smaller than 1 will vanish, while eigenvalues greater than 1 will diverge. We have numerical instability which will cause either vanishing/exploding gradients. Finally, notice that depends on and through hidden states , so we get:
Again, any numerical instability from quantity will show up in both and .
Training an RNN is the same as any other NN. We alternate between forward passes and backprop through time. Any intermediate values are cached, i.e. is stored in memory to compute and .
Strategies to Handle Numerical Instability
First, we could do the full backprop computation. But then we are giving up on finding robust models which will generalize well. As a result of the instability, small perturbations in initial conditions can lead to vastly different updates and hence final models.
Second, we can truncate the summation in after some number of steps. For example, one could detach the gradient after a given number of time steps or between mini-batches. The model focuses on short-term influences rather than long-term influences. People have found this bias is desirable as it leads to simpler, more stable models.
A more complicated truncation approach is randomized. Specifically, define a sequence with parameter where and , so . We then define:
Notice that , but whenever , we do not unroll the recursion. So, only rarely do we get very long chain rule sequences. By re-weighting long sequences up in a clever manner, one can get such a scheme to provide unbiased gradient estimates.
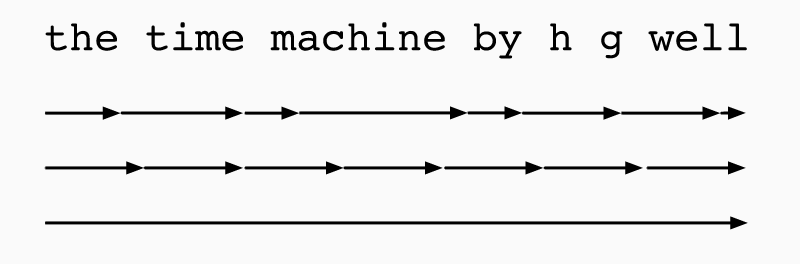
From bottom up, the picture shows these three strategies for analyzing the few words of a text. In practice, the regular truncation works best. It sufficiently captures the relevant dependencies, it is lower variance than the randomized strategy and has a desirable regularization effect.
Gradient Clipping
In RNNs, a well-known issue is unstable optimization. For a sequence length of , the gradient will involve a chain of matrix-products of length during backprop. Since this product involves the same matrices over and over again, we can have the vanishing/exploding gradients problem.
One issue you can face is that once in a while your gradients can get too large and your algorithm diverges. A reasonable approach to use gradient clipping:
So, now and the gradient points in the original direction. It also has the nice side-effect of robustifying optimization to a given minibatch or particular sample. Sometimes people do compute the gradient norm over all the parameters in the sample.
Gated Recurrent Units (GRU)
We know that long products of matrices can lead to vanishing/exploding gradients. To get better control of our gradients, we may want to add the ability to: store early vital info which otherwise would need a large gradient to exert influence, slip irrelevant tokens and forgetting our internal state representation when there is a logical break in the sequence.
To address these concerns, GRUs support gating of the hidden state. Specifically, it introduces learned mechanisms for when a hidden state should be updated and when it should be reset.
Reset and Update Gates
Consider a mini-batch of samples. Reset gates, , will help capture short-term dependencies in sequences. Update gates, , will help capture long-term dependencies in sequences. They are computed as follows:
The sigmoid functions transform the input values to vectors with entries in . This will let perform convex combinations, i.e. treat the values as weights.
Candidate Hidden States
The reset gate controls how much of the previous state we might still want to remember. It gets combined with the regular hidden state updating mechanism to get the following candidate hidden state :
The ensures the values remain in the interval . Notice that if , then is just an MLP result with the input . The pre-existing state is reset! If , we recover the original RNN set-up. This is a candidate hidden state because we still have no accounted for .
Hidden State
The updated gate will control how much of the new state is just a copy of the old state and to what degree the new candidate state is used. We get:
When , the new candidate state is irrelevant and we just keep the old state . So, information in is ignored, effectively skipping time in the dependency chain. Whn , the new candidate state is all that matters. This flexibility can help us solve vanishing gradient problems and capture long-run dependencies. If for a while, the hidden state close to the beginning can easily be retained and passed down the subsequence.
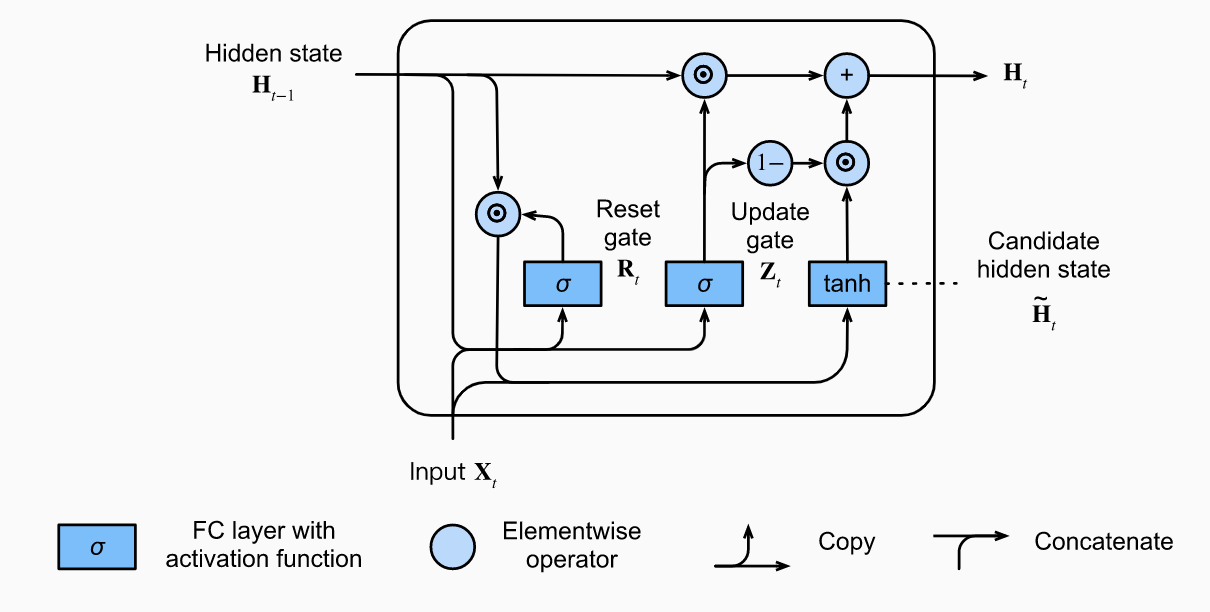
Long Short-Term Memory (LSTM)
LSTMs much like GRUs care about long-term information preservation and short-term input skipping.
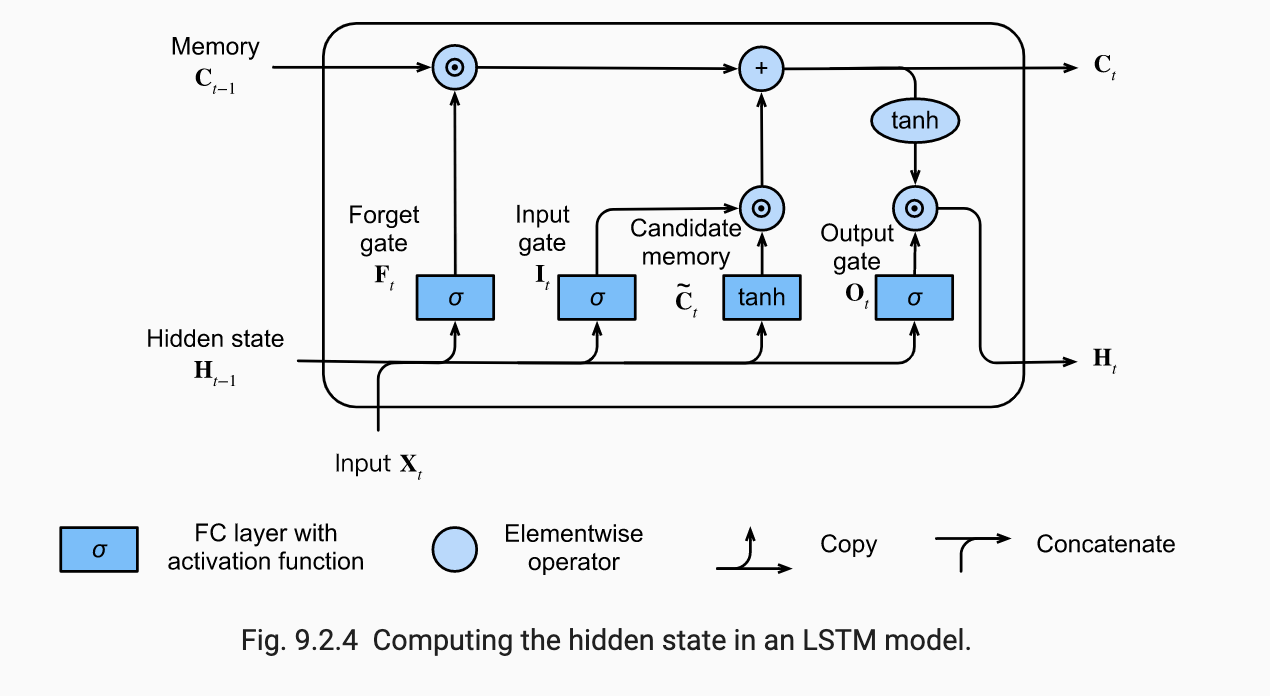
Gated Memory Cell
A memory cell records additional information about when to remember and when to ignore inputs in the hidden state. However, it is not passed to the output layer. It exists exclusively for state control. In it, we have the input gate (decides when to read data into the cell), forget gate (decides to reset the cell) and output gate (reads entries out from th cell).
Notice all these values are in due to the sigmoids. The candidate memory cell is given by:
Now, the input gate will govern how much we take new data into account via and the forget gate address how much of the old memory cell content we retain. We get:
Hence if and , the past memory cells will be saved over time and passed to the current time step. This captures long-run dependencies and solves the vanishing gradient problem.
Hidden State
THe output gate finally comes into play for the hidden state. We have:
Notice that the values of are always in . When , we pass all the info from the memory cell into the predictor. Else if , we retain all the info within the memory cell.
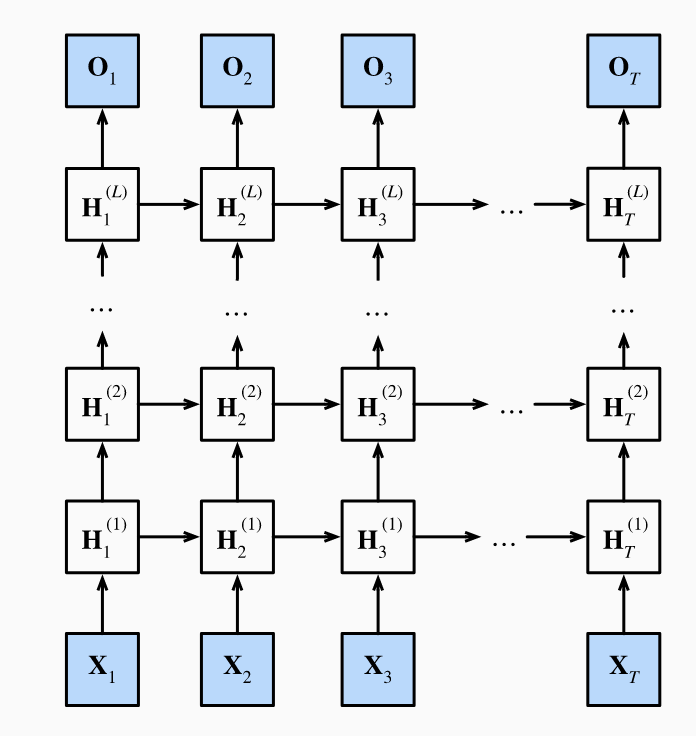
Deep RNNs
All the RNNs above have a single unidirectional hidden layer. GRUs and LSTMs specify how the inputs and latent variables interact within the hidden layer in different ways. Such specifications can be fairly arbitrary. But to create even more flexibility, we can stack several hidden layers on top of each other. Intuitively, we may think particular types of information is relevant at different levels of the stack. For example, maybe higher levels record macro-level trends, while the lower-levels keep track of shorter-term dynamics.
In a deep RNN with hidden layers, each hidden state is passed both to the next time step of the current layer and the current time step of the next layer. For simplicity, consider RNNs. For each hidden layer , we have:
Here we have , and . The calculation at the output layer just depends on the last hidden layer:
By simply replacing the hidden state computation with GRUs or LSTMs, we can get a deep gated RNN. Overall, ensuring proper convergence of deep RNNs requires careful settings for the learning rate, proper initialization and gradient clipping.
Bidirectional RNNs
Most sequence learning problems, we want to model the next output given what we have seen so far. But there are problems where we may see the future and want to infer the past. For example, consider fill-in-the-blank tasks where longer-range context may be useful. In HMMs, one can combine forward and backward recursions to infer where form a sequence of outputs generated from hidden states . We can similarly learn from the future with bidirectional RNNs.
Instead of only running an RNN in forward mode from , we also run an RNN in reverse from . Another hidden layer is added to process information in the backward direction more flexibly. Formally, the forward and backward hidden states are given by and . We have:
Next, one concatenates and to get the hidden state which is fed to the output layer. We have:
where . In deep bidirectonal RNNs, you can pass the hidden states as inputs the next forward/backward layers. Also, the two directions can have different numbers of hidden units.
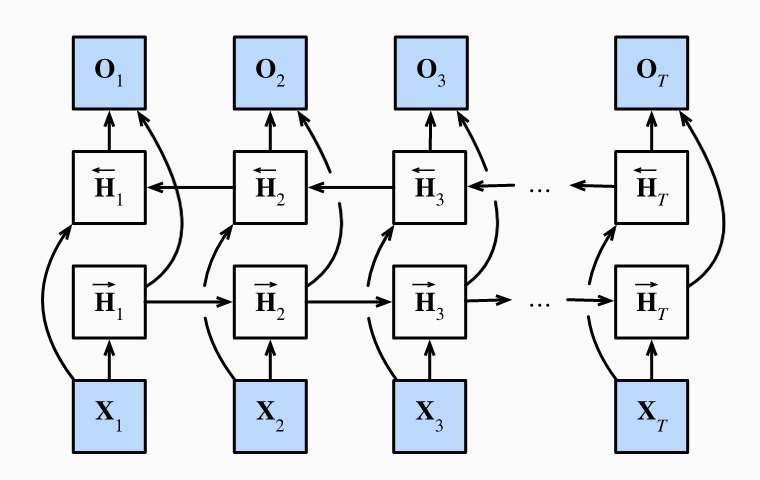
If you train a bidirectional RNN and then test it on a next token prediction problem, you will see poor performance. The model only has access to past data, but its parameters were optimized for having both future/past data. Training these models is also very slow because the forward pass requires both forward and backward recursions and backprop depends on these values creating gradients with long dependency chains.
RNN Encoder-Decoder Architecture
For modeling input/output sequences, an encoder-decoder architecture makes sense. The encoder takes the variable-length input and maps it to a fixed length state. The decoder takes this fixed length state and transforms it to a variable-length output.

For machine translation, the encoder and decoders are typically RNNs. Info on the input sequence is encoded in the hidden state of the RNN encoder. A RNN decoder generates the output token by token based on the tokens it has seen/generated plus the hidden state from the RNN encoder. Below there are two special design decisions regarding the start of the RNN decoders. First, there is a <bos> token used as an input. Second, usually the final RNN encoder hidden state is used to initiate the hidden state of the RNN decoder. Here it is taken as an input in all time steps. Notice the RNN decoder can stop making predictions once it generates <eos>. Here the labels are just the original output sequence shifted by one token.
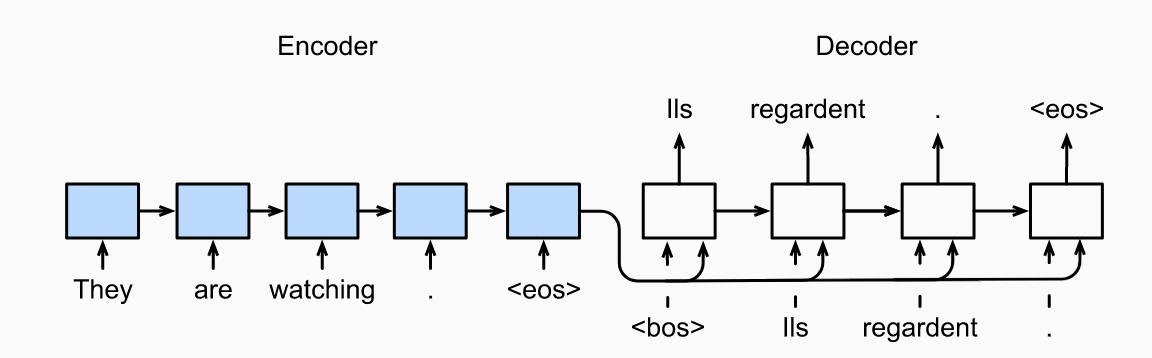
Encoder
More precisely, the encoder transforms the input sequence into a fixed-shape context variable :
using an RNN. Taking would mean the context variable is just the final hidden state. If one used an LSTM, would include both the hidden state as well as memory cell. In one used a GRU, would just be the hidden state.
Decoder
We can think of the decoder as modeling where is the output sequence. At each time step , the RNN takes , the previous hidden state and the previous output , transforming them into the new hidden state . We have:
After obtaining , we can use an output layer plus softmax operation to compute .
Implementation Details
- To initialize the hidden state of the RNN decoder with the final hidden state of the RNN encoder, we have to ensure both of them have the same number of layers and hidden units.
- To have the context included in the all RNN decoder time steps, we have to concatenate it to all the decoder inputs.
- In addition to the context, there is some flexibility on what to pass as decoder input during training. We could pass a concatenation <bos> and the original output sequence excluding the last token. This is called teacher forcing. Alternatively, we could also pass the predicted token from the last step as input to the current step. During test, we do not have access to the original output sequence, so we have to just past the last predicted token. The test time process is shown below.
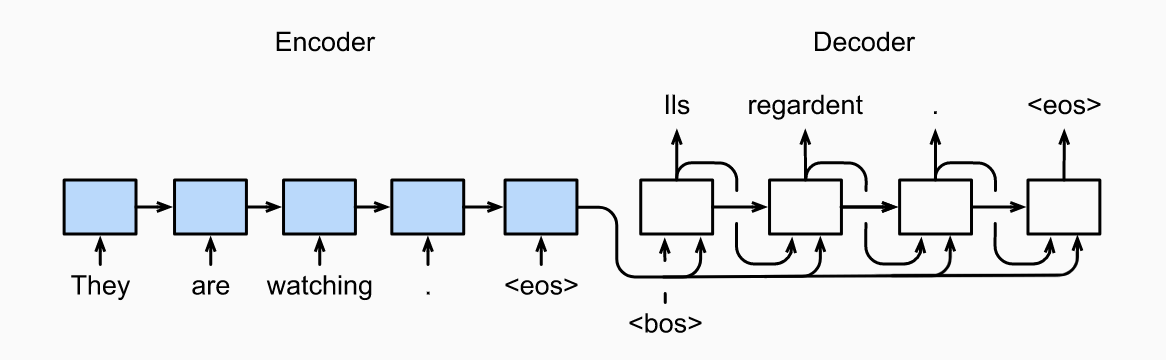
- You do not want the padded tokens to affect your loss function, so you use a mask option which zeros out irrelevant entries.
Output Sequence Search Strategies
In machine translation, we are interested in a search problem for the output sequence. Say the maximum output sequence length is . Given an output vocabulary of , the goal is search from the ideal sequence in a universe of sequences. The actual outputs will remove the portion including and after the <eos> token.
Greedy Search
In greedy search, we generate the output sequence by setting the output at each time step with the following rule:
Once <eos> token is generated or the length of the output sequence reaches , the sequence is done. The optimal sequence is the sequence with the maximum value for . However, greedy search is not guaranteed to return this optimal sequence.
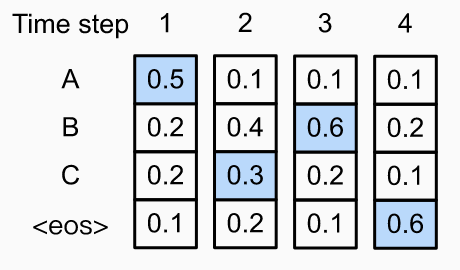
Consider the example below. Both images show the time steps on the horizontal axis and the conditional probs on the y-axis. The blue boxes are possible outputs. In the first case, the output is ABC<eos> with prob . This is the choice selected by greedy search. In the second case, the output is ACB<eos>. Because the second output char is different, the conditional probs of the later time steps changes. The prob here is , so it is better than the first choice.

Exhaustive Search
Exhaustive search will be computationally infeasible since it requires evaluating the probs of all sequences. Notice that greedy search only has a complexity of which is much better than .
Beam Search
Beam search can optimize the tradeoff between accuracy and computational cost. There is a hyperparameter, , called beam size. At time step 1, we select the tokens with the highest conditional probs. At each following time step, we continue by selecting candidate output sequences with the highest conditional probs from the choices. The image below shows the process for , and . We start by picking and since for all , they maximize . In step 2, for all , we compute:
Among the ten choices, the top two are and . The last step is similar.
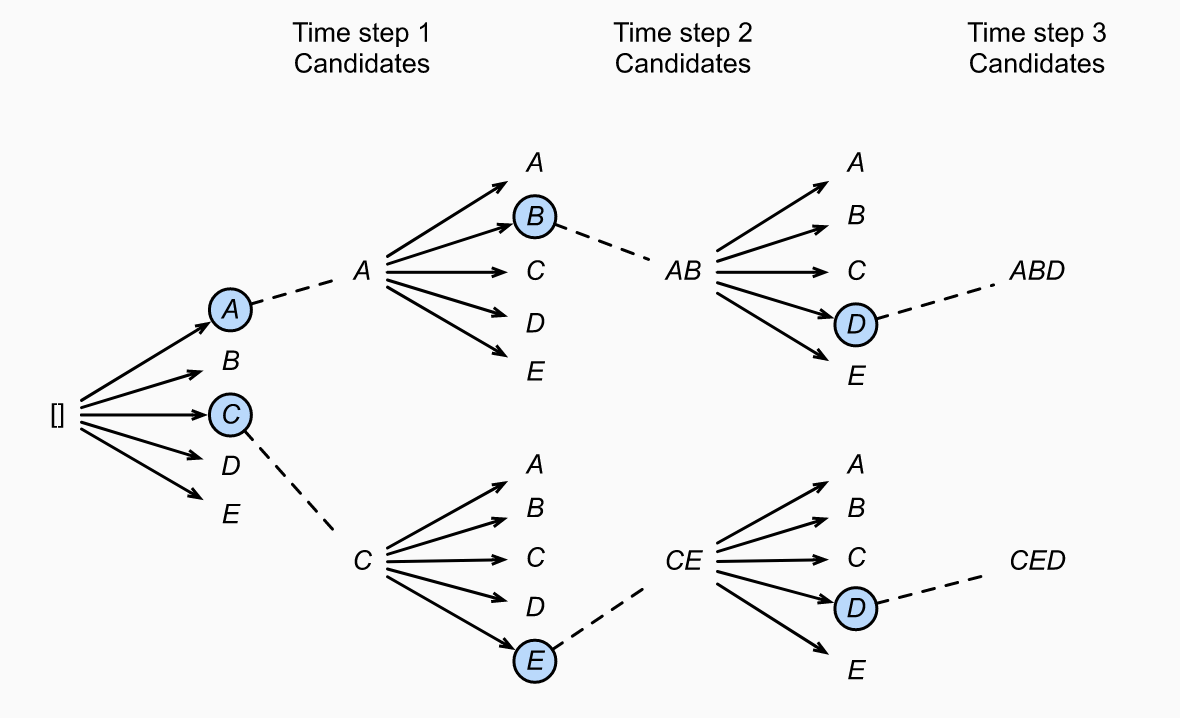
Over this full process, we have generated six candidate output sequences: , , , , and . After discarding the tails of sequences including and following <eos>, we choose the sequence which maximizes:
where is the length of the sequence and . The term helps longer sequences which will have more (negative) terms in the summation.
The compute cost of beam search is . Greedy search is just beam search with .