Optimization for Deep Learning
This is part 2 of my applied DL notes. I am taking an optimization course this upcoming fall which will cover the more theoretical aspects of optimization and relevance to modern ML. These notes will only convey very high-level intuition of these algorithms and practical advice as relevant to DL. A great supplementary blog post is here.
Overview
Most classical optimization methods are designed for convex optimization. Essentially, all multi-layer NNs with non-linear activations are non-convex in the trainable parameters . That is the Hessian is neither PSD or NSD everywhere. There are many local minima, many global minima (in the overparameterized case) and saddle points. In high dimensions, the likelihood that at least some eigenvalues at a zero-gradient point are negative and positive is quite high, which makes saddle points more common than local minima. While training NNs is solving a non-convex optimization, many of the intuitions from convex optimization carry over. Importantly, your choice of hyperparameters and algorithm play a much more important role on the solution to which you converge, the speed of convergence and the generalization properties of the solution.
Classical Methods
Gradient Descent
Recall the GD Lemma tells us that for any -smooth function (convex or not), as long as :
So, using the proper learning rate, as long as we have a non-zero gradient, we can decrease the objective. If and is convex, we are set since . But in general, GD Lemma only gives convergence in the norm of the gradient. We are guaranteed to find a point such that in less than:
steps. Convergence in actual function value requires convexity, in which case the Mirror Descent Lemma gives the convergence rate:
To find a solution with accuracy requires steps. For a strongly convex function this improves to .
Second-Order Methods
Consider an example from ZLLS2021 where . Running GD leads to a solution path as follows:
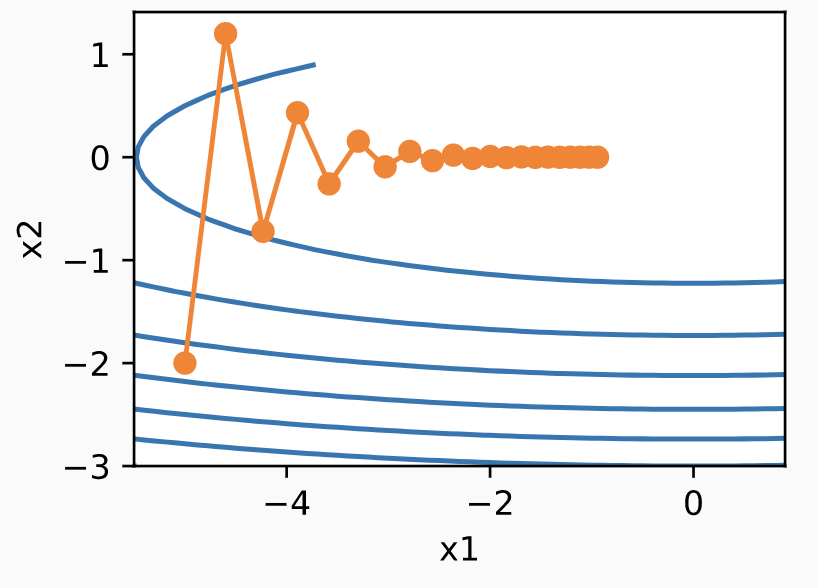
Since the function has a lot more curvature in the direction compared to the direction, the local gradients will zig-zag and only very slowly reach . The function here is 2-smooth, so GD one converges when . Second-order methods attempt to adapt to the local geometry/curvature of a function to handle this issue and get faster convergence rates.
The idea behind Newton’s method is that instead of approximating a function locally with a first-order Taylor expansion (a linear approximation), one uses a second-order Taylor expansion (a quadratic approximation) which yields the optimal update:
Intuitively, one can think of this update as scaling the learning rate in different directions depending on the curvature of . Directions with more curvature get scaled down more; directions with less curvature get scaled up. In general, Newton’s method only has a local convergence guarantee. Once you are close enough to (at step ), you get quadratic convergence. Specifically for :
where depends on the smoothness of and its gradients. To find a solution with accuracy requires O() steps. Alternatively, one can see that the number of digits to which the solution is accurate for doubles in each step. For strictly convex functions, global convergence guarantees are possible but only at the rate.
For large-scale ML, second-order methods are infeasible because scales quadratically with the number of parameters in your model. Further, inverting such a matrix is can be extremely expensive. A possible solution is to approximate the Hessian with another pre-condition matrix , for example . Additionally, for non-convex problems where the Hessian can have negative values, without any adjustments, Newton’s method may increase the function value.
Line Search
Often GD and Newton’s method are complemented by line search to ensure that each iteration does not overshoot. That is once, and have been computed, one finds an adaptive learning rate which sufficiently decreases . One can do this in a binary search approach. Again, for large-scale ML this is infeasible because it requires evaluating the objective function of a potentially very large dataset.
SGD
For an ERM problem, our objective function looks like:
where is the loss on a training point . Running GD on this function would require computation for parameter dimension . This is infeasible for a large datasets. An alternative is SGD which samples a single point at random to approximate . Note that assuming iid data, we have . We have a noisy estimate of the true gradient.
We get the following convergence rate for convex :
where and . Here we see the variance of the stochastic gradient, , plays an important role in the convergence.
The result above relies on sampling with replacement from your training data. However, in expectation, we will only see 67% of the training data. In practice, SGD is run by sampling without replacement but in each epoch the samples are passed through in a different random order.
Mini-Batch SGD
One strategy to reduce the value of is to use larger batch sizes when using stochastic gradients. That is we use the following updates:
Say . Increasing the batch size from 1 to reduces by a factor of (even when sampling with replacement) and hence improves the convergence rate by a factor of . But per iteration we need to compute more gradients. There is a statistical-computational tradeoff here which seems to suggest not increasing batch sizes.
However, this perspective ignores the computational advantages due to vectorization and efficient use of cache. The compute cost does not in fact scale linearly with . The simplest example to demonstrate this idea is parallelization across multiple GPUs and servers. If we have 16 servers with 8 GPUs, sending 1 sample to each, we can compute the update for a minibatch of 512 samples in the same time as a single sample. Issues are a bit more subtle when dealing with a single GPU or CPU. A CPU has a small number of registers, than L1, L2 and sometimes L3 cache. These caches increase in size and latency and decrease in bandwith. The key idea is that processors are able to perform many more operations than what the main memory interface can provide it. A 2GHz CPU with 16 cores and AVX-512 vectorization can process upto bytes per second, but a typical processor might have a bandwith of only 100 GB/s. That is one-tenth of what would keep the processor fed. Moreover, not all memory access is created equal. For example, sequential access tends to be faster than first access. The fix here is to avoid loading new data from memory as far as possible and store it locally in CPU cache. With the standard minibatch sizes and vectorized matrix computations, DL libraries can do exactly that. It is useful to set the mini-batch size to a power 2 since that is how computer memory is layed out and accessed.
Accelerated Gradient Methods
The core idea behind accelerated methods is to somehow average the current gradient, , with previous gradients. These methods, much like second-order methods, can adapt to the local curvature of a function. Additionally, they can reduce the variance of stochastic gradients, finding more stable descent directions.
The standard technique is momentum. Let denote the standard gradient update (possibly computed by full-batch or minibatch SGD). The simplest implementation would be to use where is defined as:
for some . Expanding reveals:
That is our current update, , amounts to an exponentially-weighted moving average of the standard gradient updates.
Intuitively, momentum increases the effective learning rate in smoother directions of our parameter space and decreases the learning rate in directions with more curvature. For example, consider the ill-conditioned problem shown in the “Second-Order Methods” section. The coordinate of associated with will be reduced by since the signs of updates are switching back and forth. On the other hand, the coordinate of associated with will increased by since the signs of the updates are all in the same direction. Note that . Hence, as , we are effectively using a larger learning rate than permitted by GD along with better behaved descent directions.
A variant of of the usual momentum is more theoretically amenable. For this variant, we have the following result. Assume and . For , we need at most steps to find such that . GD needs to find such a point.
GD vs Momentum in Eigenspace for Quadratic Functions
G2017 have a useful explanation of why momentum works beyond basic intuition. Here we cover one of the most basic results the article conveys. Consider the convex quadratic function:
For PSD matrices, , the minimizer is and . Then, we can write as follows:
The gradient . Now consider the eigendecomposition of and change of variables . That is is the distance to the minimizer represented with respect to the eigenvectors of . Now, we have:
where . Now, we have GD gives:
Hence GD does not mix between eigenspaces. In the original space, we have:
Here we see that the optimization proceeds in a coordinate-wise manner with respect to the eigenvectors of . Each element of is the component of the error in the initial guess with respect to the eigenbasis . Each such component independently follows a path to the minimum, decreasing at a exponential rate of . So, convergence in the directions of the large and small eigenvectors occurs fast and slow, respectively. In order to converge, we need for all . All valid must obey:
The overall convergence rate is determined by:
This rate is minimized when the rates for and are the same, which gives an optimal and an optimal rate:
Hence the convergence rate is determined by the condition number of .
A similar analysis for momentum reveals:
We can write this update in a component-wise fashion with the following:
With some linear algebraic tricks, one can write in terms of its eigenvalues, and . This analysis shows that the rate of convergence is determined by . Valid values for and obey:
Here we see that momentum allows us to increase the learning rate by a factor of 2 compared to GD before diverging.
AdaGrad
Imagine a very large scale NLP model. A common problem is sparse features. It is clear that some words occur very frequently while others are rare. If we use a fixed learning rate schedule with a rate, we will see many more parameter updates for frequent features, while convergence for infrequent features will lag behind. AdaGrad addresses these issues by using a learning rate of the form where . Coordinates with consistently large gradients are scaled down a lot, while coordinates with small gradients are scaled up.
The benefits of AdaGrad are best understood in context of approximate second-order methods and pre-conditioning. Recall from the discussion above on GD in eigenspace, that the convergence rate is driven by . For the convex quadratic problem, we could in theory improve the convergence rate by a change of basis . But this modification requires computing the eigenvectors and eigenvalues, which is much more expensive than solving the original problem itself. Another solution would be use . In this case, we have and . In practice, this improves the condition number considerably.
The solutions above do not work for DL because we typically do not have access to the Hessian of the objective function and computing it for a given requires time and space to compute, which is infeasible. AdaGrad approximates the diagonal of the Hessian by using the magnitude of the gradient itself. Recall for the convex quadratic objective we have . So, the gradient depends on and , which measures distance from optimality. If were fixed as a function of , then that is all we need. With SGD, we will see non-zero gradients even at the optimum. So, AdaGrad uses their variance as a proxy for the scale of the Hessian.
In practice, the AdaGrad updates look as follows:
All these updates are done coordinate-wise. The is a small number to avoid divide by zero errors. Since grows at a linear rate, we see that AdaGrad corresponds to a rate on a per-coordinate basis. An issue in DL is that this schedule might decrease the learning rate too aggressively. The variants below address this problem.
RMSProp
Note that is unbounded and grows at a linear rate. RMSProp attempts to decouple learning rate scheduling from coordinate-wise adaptive rates. The idea is to normalize . Just like momentum, one way to do normalize is with leaky averages:
The above formulation allows to control the learning rate schedule independently of the per-coordinate basis scaling. Note that we have:
Since , the sum of the weights is normalized to 1. In practice, and .
AdaDelta
AdaDelta is another modification of AdaGrad which eliminates the need for an initial learning rate all together. Intuitively, updates to parameters should be in the units of the parameter. For example, if a parameter represents years, updates should also be in units of years. However, this is not the case for many of the algorithms above. For example, for GD and momentum, we have:
In AdaGrad, the update is unitless. Newton’s method gets this right. We have:
AdaDelta uses a rescaled gradient which similarly has the correct units. To do so, we keep track of both a leaky average of second moment of the gradient like RMSProp as well as a leaky average of the second moment of the changes in the parameters themselves:
where is the rescaled gradient:
So, AdaDelta can be viewed as attempting to approximate Newton’s method or automating the choice of .
The update we use is .
Adam
Adam combines many of the merits of mini-batch SGD, momentum and RMSProp into one algorithm. It is one of the go-to optimization techniques in DL today, but does not have any convergence guarantees (even for convex problems. In practice, Adam works well for training NNs.
Adam keeps track of two EWMAs: one for momentum and one for the second moment of the gradient:
Common choices are and , so the variance term moves much slower than the momentum term. Initializing creates significant bias towards small values. Using , we can normalize the state variables as:
The update equations are:
These are similar to RMSProp, but with two differences. First, one uses momentum instead of the usual gradient. Second, there is a minor re-formulation of the denominator, which works slightly better in practice. Typically, .
In summary, Adam takes advantage of momentum and scale (per the state variables) to get faster, more stable convergence. There is a de-biasing component to handle the initialization and EWMA. Finally, per RMSProp, the learning rate is de-coupled from the coordinate-wise scaling.
Yogi
Adam can diverge when the second moment estimate in blows up. We can re-write the Adam update as:
If has high variance or updates are sparse, then may forget the past quickly. Yogi proposes the following update instead:
Note here the magnitude of the update no longer depends on the size of the deviation. In Adam, when is much larger than , the effective learning rate increases rapidly. In Yogi, when is larger than , the effectively learning rate also increases, but in a much more controlled fashion.
Dynamic Learning Rates
Learning rate scheduling is more important for non-convex problems compared to convex problems. Some considerations here are:
-
Recall the magnitude of the optimal learning rate is to some degree determined by the “condition number” of the problem.
-
When using stochastic methods like SGD or minibatch SGD, dynamic learning rates become important. Even when one is close to the optimum, noise in the gradient can make it difficult to converge. Setting the learning rate too large and you will overshoot the optimum. On the other hand, setting the learning rate too small can stall convergence earlier in the process. For convex problems, we typically set a schedule at a rate, but for DL, we may want to decay faster.
-
Warmup: Large steps at the beginning may not be useful because we use random initialization.
-
Generalization: There is some theoretical backing supporting the idea that small step sizes improve generalization by preventing memorization in DL tasks.
While many of the algorithms we considered above (momentum, AdaGrad, etc.) do some form of adaptive learning rate adjustment, they typically still require a learning rate schedule and this additional lever can be important to get good test performance.
Some common strategies for adjusting are as follows:
In the first scenario, the learning rate is decreased whenever optimization stalls in a piece-wise constant fashion. That is once we reach a stationary point in terms of the distribution of the weight vectors, we decrease the learning rate to obtain a higher quality proxy to the a good local minimum. This is common in DL. The exponential and polynomial schedules are natural choices with theoretical guarantees for convex problems. The last policy is the cosine scheduler. Here is a target rate for time . The idea is that we may not want to decrease the learning rate too much in the beginning and may want to refine the solution in the end using a very small learning rate. For , the learning rate is simply pinned to .
For complicated architectures, warmup is an important concept. Taking large steps early can be problematic since random initialization can cause the algorithm to diverge early for those parts of the network that aare the most difficult to optimize. Instead, one can linearly increase from a learning rate of 0 to the initial maximum in a number of “warmup” steps before implementing the desired policy.
Optimization Checks
Gradient Checking
In most cases, you will rely on your DL framework’s built in autodiff functionality to do backprop. There are some exceptions where you may implement your own backward function. For example, if you have a function that cannot be expressed as composition of other differentiable functions or if you have a shortcut to speed-up a particularly complicated chain rule.
Gradient checking ensures your backprop calculation is correct. You comapre the analytic gradient to the numerical gradient. Some tricks to make sure you are doing this robustly:
First, use the centered formula: where is a small number such as . This is a better gradient approximation than the usual formula because it is a second-order approximation and has error on the order of instead of .
Second, use the relative error for comparison:
If the relative error is less than , you are probably okay. Else, there may be something wrong. Also, note the relative errors will tend to increase for larger/deeper NNs.
Third, sometimes a gradient check might fail even though it is correct due to issues with numerical precision. To prevent this, use double instead of single precision floating point numbers. Also, stick around the active range of floating point. That is your loss on a minibatch is tiny (less than ), then it may make sense to scale up your loss function by a constant to a nicer range where floats are more dense. Finally, be careful with . Too small a can run into issues due to cancellation.
Fourth, kinks in your objective can cause issues with gradient checks. Consider gradient checking the ReLU function at . It will have a gradient of zero, but if , then will introduce a non-zero contribution to your numerical approximation. One solution here is to only use a few datapoints since the loss function will contain less kinks and you are less likely to cross a threshold doing the numerical approximation. This also speeds up your gradient checking process.
Fifth, do gradient check during a “characteristic” mode of operation. A gradient check can succeeed at a particular random point in parameter space even if the gradients are not implemented properly globally. This can be due to pathological edge cases caused by small initializations near 0. It is good to train your model for a while and let the loss decrease in a burn-in period. From then, you can run the gradient checking process.
Sixth, if you include weight decay the regularization loss can overwhelm the data loss. This can make it look like your gradient checks are passing because of the regularization term (with the more easily computable gradient) is correct, even though your data loss terms are incorrect. A solution would be to turn off regularization and run the checks. Then, independently check the gradients due to the regularization loss.
Seventh, turn off non-deterministic effects in the network such as dropout or random data augmentations. Otherwise, this can introduce huge errors in the numerical gradient. But in that case you are also not checking these features (i.e., dropout may not be backpropogated correctly). A better solution might be to force a particular random seed before evaluting , and the analytic gradient.
Other Sanity Checks
In addition to gradient checking, it is a good idea to run a few more general sanity checks before trying an expensive optimization.
First, often given the number of classes in your dataset, the fraction of points in those classes and your loss function you can calculate the loss on a model initialized with zero weights. Make sure you see the actual loss matches up. For example, for CIFAR-10 softmax classification the initial should be 2.302, because there are 10 classes each with fraction around 0.1 and .
Second, increasing regularization should increase your training loss.
Third, overfit a tiny subset of the data. Use 20 samples from your training data and make sure you can get to zero loss. It is possible you pass this check, but the NN is still incorrectly implemented.